Published: Apr 20, 2020 by Shin Young Kim
GSx Active Learning
A problem I had with datasets having small amount of samples(for the sake of simplicity I set a criteria of <30) was that it’s hard to get reasonably accurate prediction results.
Apparently, one of the methods used in said scenarios was Active Learning. Active learning is a method where given a set of data points, it only chooses up to points, either by manual selection or a set criteria. It’s often used in scenarios where data is abundant that not all can be labeled.
However, as I’m primarily dealing with time series, I wasn’t sure if it was acceptable to selectively omit some data points.
I found a paper named Active Learning for Regression Using Greedy Sampling by D. Wu et al., using simple greedy techniques to select data points for training.
The first method the paper mentioned, named “Greedy Sampling on the Inputs(GSx)”, would select data points which is the closest to the centroid of all the samples. This is iterated times, resulting in the training set.
I tested the method with “Total number of phone calls to pizza delivery services from Seoul area in September, 2019” data. The data consists of daily number of phone calls from September 1st to the 30th, separated by age group(10, 20, 30, …) and district. Since I was only interested in the total number of calls, I deemed that age group and district would be irrelevant in the results. So my formatted data consists of 30 data points, one for each day.
GSx was implemented by using the absolute distance from the mean of the standarized values, which would be the absolute distance from 0. The data was divided into 24 train data points, and 6 test points. Additionally, the data showed a strong weekly seasonal frequency.
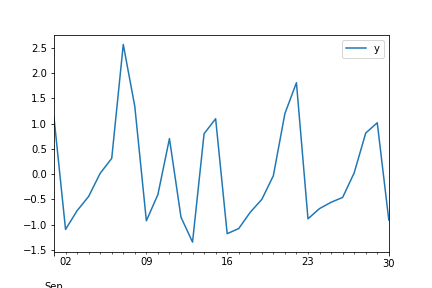
data plot, standardized
A standard Linear Ridge model was used, with a Piecewise Trend and a Weekly Fourier feature added. I started with an initial value of , up to the length of the train set, 24.
The results are shown in the image below(The numbers next to k is the RMSE):
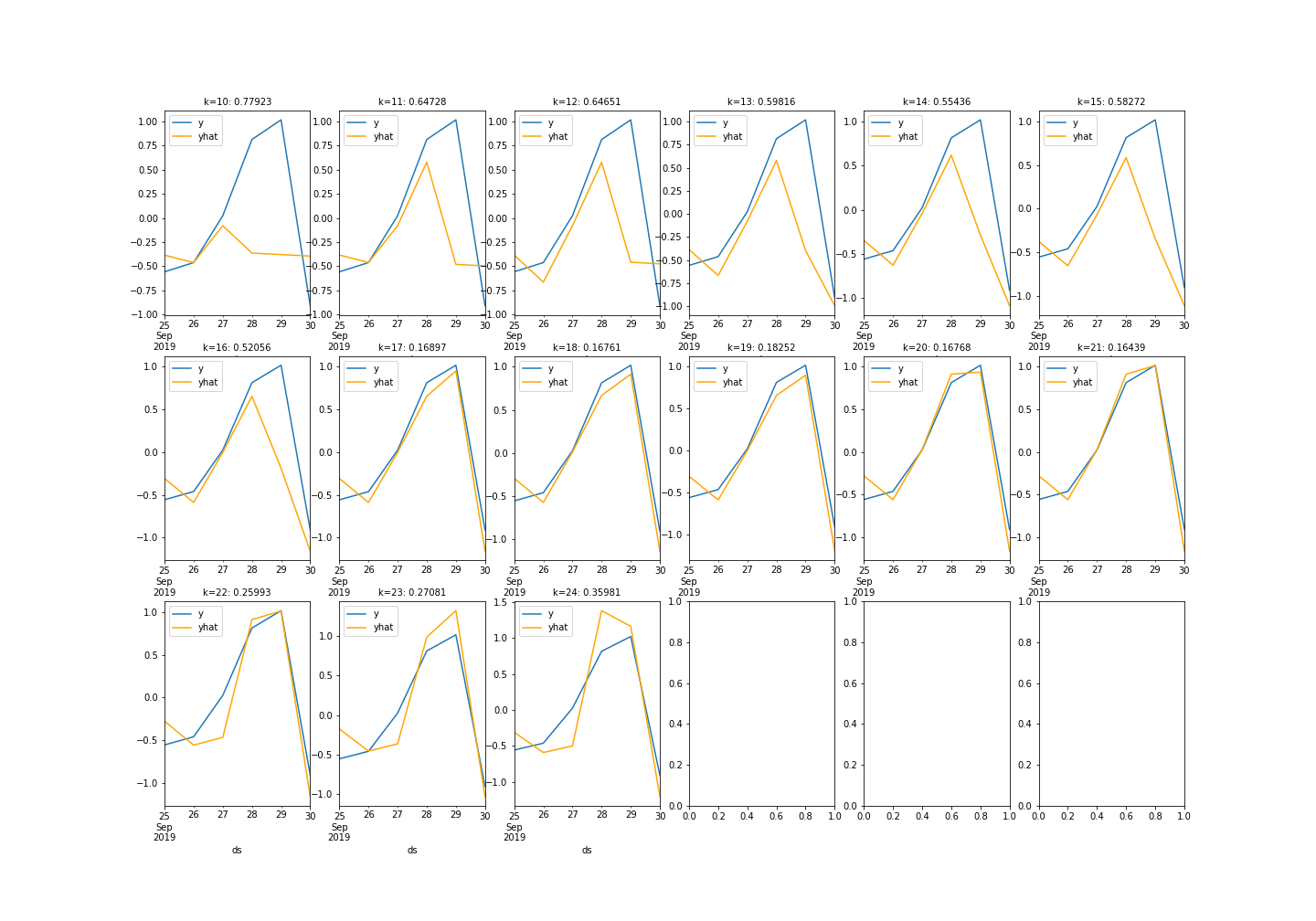
As you can see, the RMSE score peaks at , but interestingly enough, adding more data points actually increased the error.
Even though GSx is a simple technique, it was able to increase the accuracy in a test environment. Additionally, other methods, such as GSy in the aforementioned paper, or more advanced ones, could possibly bring even better results.